
What Are AI Weights and Open Models? A Plain-English Guide to What They Now Let You Do
What is a weight in an AI model?
Strip away the mystique and an AI model is, at heart, a gigantic pile of numbers. Those numbers are the weights.
Here is the intuition. When a model is trained, it reads an enormous amount of text and slowly adjusts billions of internal dials so that it gets better at predicting what comes next. Each dial is a weight. A single weight on its own means nothing, but billions of them, tuned together, encode everything the model has learned about language, facts, code, and reasoning. When people say a model has 70 billion or 700 billion parameters, the parameters are those dials.
A useful way to picture it: if the model were a brain, the weights would be the exact strengths of all the connections between its neurons. Training is the slow process of setting those strengths. Once training is done, the weights are frozen, and that frozen file of numbers is, quite literally, the model. Running the model just means feeding your question through all those numbers to produce an answer.
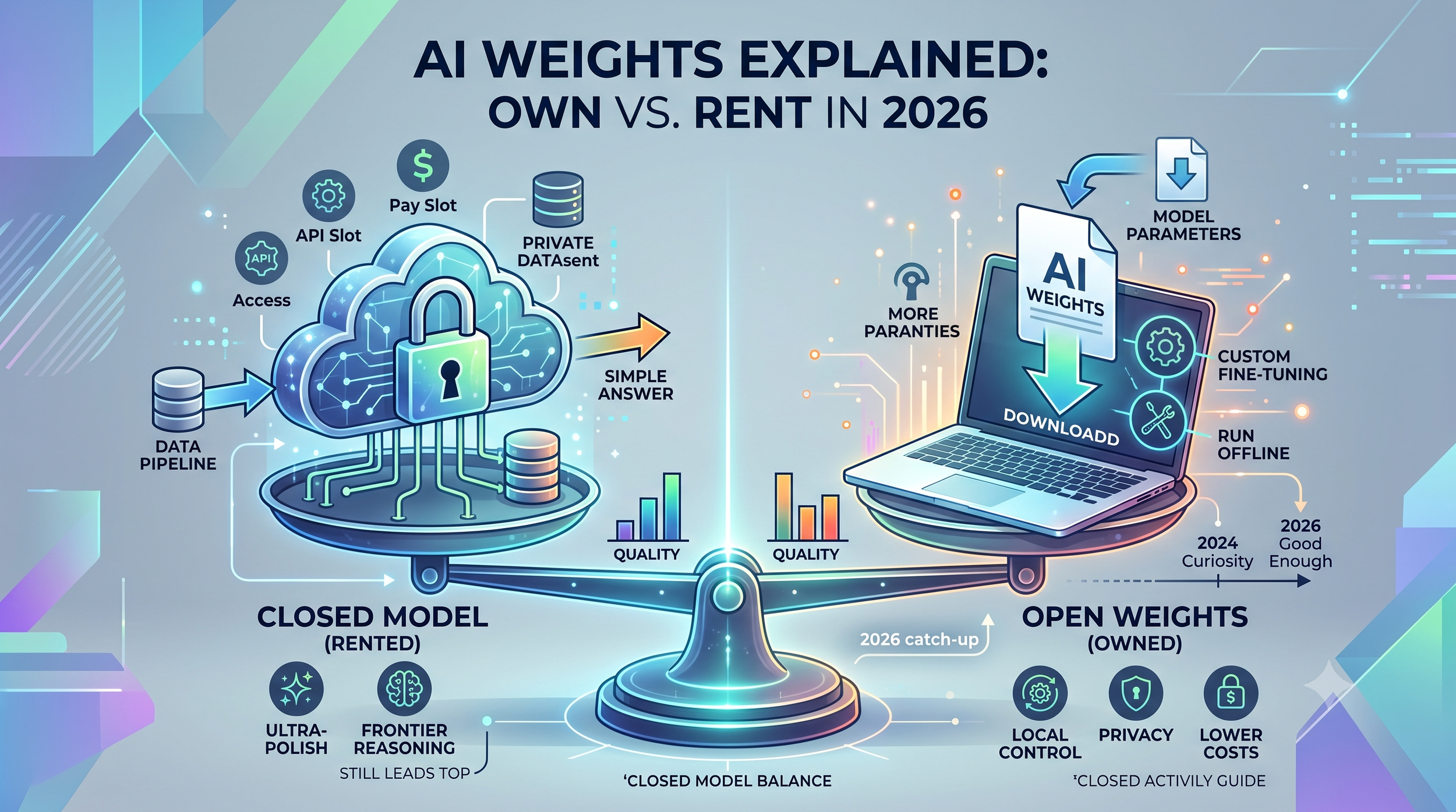
This matters for one simple reason. If you have the weights, you have the model. You can run it, copy it, study it, or modify it, all on your own equipment, with no permission needed from whoever made it. If you do not have the weights, you can only use the model through whatever door its owner opens for you, usually a paid connection over the internet. That single distinction, who has the weights, is what the entire open-versus-closed debate comes down to.
So what does an open model actually mean?
This is where most explanations get sloppy, and getting it right is the difference between understanding the field and being misled by marketing. There are two different things people lump together under the word open, and they are not the same.
Open weights means the company released the frozen file of numbers. You can download it, run it on your own machine, and modify it. But they did not necessarily tell you how they made it. The recipe, meaning the training code and especially the gigantic dataset the model learned from, stays private. You get the finished cake, not the recipe.
Open source, used strictly, means everything is released: the weights, the training code, and the data. In principle you could reproduce the whole model yourself from scratch.
Here is the crucial catch. Almost every model people casually call open source is actually only open weights. The truly, fully open ones, where the data is published too, are rare. So when you read that some model is open source, assume it means you can download and run the weights, not that you can see what it was trained on.
There is a second trap: open does not automatically mean do whatever you want. The permission attached to a model is set by its license, and these vary enormously. Some of the most popular models use very permissive licenses, often named Apache or MIT, which let you use, modify, and sell products built on them with no fees and no restrictions. Others look open but carry real strings. One widely used family, for example, restricts very large companies and adds geographic limits. A few are released only for research and forbid commercial use entirely. The practical lesson is to read the license before building a business on a model, because open is a spectrum, not a single thing.
What changed in 2026: the open models grew up
For a long time the open models were clearly a step behind. You used them to save money and accepted that they were not as smart. That is no longer the honest picture.
The shift was fast. Industry trackers that rank models on standardized tests went from describing open weights as curiosities to calling them, in 2026, the default choice for a lot of production work. One measure of how the field tightened: the gap between the best model and the tenth-best fell from nearly 12 percent to around 5 percent in a single year. The frontier got crowded.
On the tasks that matter most to builders, especially coding, math, and handling very long documents, the leading open models now match or beat what closed providers were charging premium prices for a year earlier. The strongest open model of mid-2026, from a Chinese lab, climbed high enough to rank among the top handful of models in the world on a respected overall intelligence ranking, beating some well-known closed models on certain long coding tasks while costing roughly a sixth as much to run. Another open model reset the price floor entirely, landing close to the best closed models on real coding benchmarks at something like a thirtieth of the cost per unit of output.
Two things are worth noticing in that story. The first is that the open frontier is now largely a Chinese story. Labs like DeepSeek, Alibaba's Qwen, Moonshot's Kimi, and Z.ai's GLM hold most of the top open positions, with Meta's Llama and Europe's Mistral playing important supporting roles, alongside smaller efforts from the United States, the Gulf, and India. For some organizations the country of origin is a non-issue; for others, with compliance or data-sovereignty rules, it is a real consideration, and Western-built open options exist for exactly that reason.
The second, and this is the part my disclosure obliges me to state plainly rather than bury, is that the very top of the field is still closed. On the broadest overall rankings, the leading models from Anthropic, OpenAI, and Google still sit at the front, with the best open model a notch below. So the accurate summary is not open models won. It is open models closed most of the gap, and for a large and growing share of practical tasks, the remaining gap no longer matters. For the hardest frontier work, the best closed models still lead.
What you can actually do with open models
This is the part that turns a definition into an opportunity. Because you can hold the weights, open models unlock a set of things that a closed, pay-per-use service simply cannot offer. Here are the five that matter most.
Run one on your own computer
The headline capability is that you can run a capable AI model entirely on your own hardware, with no internet connection and no account.
It is genuinely approachable now. Free tools let you download and start a model with a single command, and add a chat interface that looks much like ChatGPT, except it runs on your machine. The only real constraint is hardware. The biggest, smartest open models need serious, expensive graphics chips, often several of them, because the whole pile of numbers has to fit in fast memory to run quickly. But the mid-sized models have become remarkably capable, and several strong ones now run on a single high-end consumer graphics card, with smaller versions running on a decent laptop. You trade some capability for the ability to run it yourself, and that trade gets better every few months.
Cut your AI costs, sometimes drastically
For anyone building a product that makes heavy use of AI, cost is often the deciding factor, and open models attack it from two directions.
First, many open models are available through cheap hosted connections, where someone else runs the hardware and you just pay per use, often at a small fraction of premium closed-model prices. For high-volume, straightforward work, this alone can cut a bill by ninety percent or more.
Second, if your usage is large enough, running the model yourself becomes cheaper than paying per use at all. The rough rule that emerged in 2026 is that self-hosting a mid-sized model starts to beat hosted pricing once you are pushing several million words a day through it, and for the largest models the threshold is much higher. Below those volumes, paying someone else per use is almost always cheaper once you count the engineering time, which is the honest caveat most cost pitches leave out. The point is not that self-hosting is always cheaper. It is that above a certain scale, owning the model removes the per-use meter entirely.
Fine-tune it on your own data
Because you hold the weights, you can keep training the model a little further on your own material, a process called fine-tuning. This nudges those internal dials toward your specific world: your industry's language, your company's tone, your particular kind of task.
This is the capability a closed service usually cannot match, at least not deeply. With a permissively licensed open model, you can take the base model, train it on your own examples, and deploy the customized result commercially without paying anyone a royalty. For a business with a narrow, repetitive, specialized job, a smaller open model fine-tuned on the right data can outperform a much larger general model on that one task, while being cheaper to run.
Keep your data private and in-house
When you use a closed model, your prompts, and whatever data you include in them, leave your building and travel to someone else's servers. For a lot of work that is fine. For sensitive material, like medical records, legal documents, financial data, or proprietary code, it can be a dealbreaker or even illegal.
An open model running on your own hardware never sends that data anywhere. The information stays inside your network, under your control. This is precisely why open models moved into production at organizations that cannot, or will not, hand their data to an outside service, and it is a large part of why interest in them grew so fast in regulated industries. For organizations bound by data-sovereignty rules about where information physically lives, running a model on their own machines, in their own country, solves a problem that no external service can.
Avoid being locked into one provider
The last benefit is strategic. If your whole product is built around one company's closed model, you are exposed: to their price changes, their usage limits, their content rules, and their outages. You are renting a critical part of your business from a landlord who can change the terms.
Open models are an escape hatch. Even if you do not run one today, the fact that capable open alternatives exist gives you leverage and a fallback. Many builders now design their systems to switch between models, keeping an open one in reserve so that no single provider holds their product hostage. Ownership of the weights, even as an option you are not currently using, is a form of insurance.
The honest tradeoffs: open versus closed
A fair guide has to be just as clear about where open models fall short, because the choice is genuinely a tradeoff, not a free win.
Closed models still lead at the very top. For the hardest reasoning, the most polished writing, and the most reliable safety behavior, the best closed models retain an edge, and they tend to feel more refined as finished assistants. If you simply want the single most capable answer and do not care about cost, privacy, or control, a closed model is often still the better pick.
Convenience favors closed too. Using a closed model is as easy as signing up and sending a request. Running an open model yourself means dealing with hardware, setup, updates, and the engineering time all of that consumes. The cost savings of self-hosting are real only above meaningful scale; below it, the convenience of paying per use usually wins once you value your time honestly. Renting hardware in the cloud to run a large open model can run into thousands of dollars a month, which only pays off if you are using it heavily.
And open is not a magic word. As covered earlier, most open models are only open-weight, not fully transparent, so you usually cannot audit what they learned from. Licenses carry restrictions that can quietly rule out commercial use or large-scale deployment. The country and lab behind a model can matter for compliance. None of these are reasons to avoid open models, but all of them are reasons to look before you leap.
Reinforcing my disclosure one more time: I am a closed model, so the natural temptation would be to frame all of this as closed-is-better. The truthful version is more balanced. For frontier-level difficulty and finished polish, closed still leads. For cost, privacy, control, customization, and freedom from lock-in, open often wins outright, and the quality gap has shrunk to the point where, for most everyday tasks, you would struggle to tell the difference.
Who should actually care
To make this practical, here is the rough decision.
If you are an individual or a small team doing general work and you value simplicity, a closed model is the path of least resistance, and that is fine. The open-model advantages mostly do not apply to you yet.
If you are a builder, founder, or agency, open models are worth real attention in four situations: when your AI costs are climbing because of heavy usage, when you handle data that cannot leave your control, when you need a model tuned tightly to a narrow domain, or when you want to avoid betting your entire product on one provider. In any of those cases, the open ecosystem in 2026 is mature enough to be a serious option rather than a science project.
The smartest posture for most builders is not all-open or all-closed. It is to use the best closed model where its quality clearly earns its price, and to reach for an open one where cost, privacy, customization, or independence matters more than the last few percent of capability. The fact that this is now a real choice, rather than a compromise you accept to save money, is the actual story of open models in 2026.
Frequently asked questions
What are weights in an AI model, in simple terms?
Weights are the billions of numbers a model adjusts during training, which together store everything it has learned. Think of them as the strengths of all the connections in an artificial brain. Once training finishes, the weights are frozen, and that file of numbers is effectively the model itself, so whoever has the weights can run and modify the model on their own equipment.
What is the difference between open source and open weights?
Open weights means the company released the model file so you can download, run, and modify it, but kept the training recipe and data private. Open source, strictly speaking, means the weights, the training code, and the data are all released so the model could be reproduced from scratch. Most models people call open source are really only open-weight.
Are open AI models as good as ChatGPT or Claude now?
For many everyday tasks, yes. By 2026 the leading open models match or beat the closed leaders on things like coding, math, and long documents, at far lower cost. For the hardest frontier reasoning and the most polished assistant behavior, the best closed models still hold a modest lead, so it depends on how demanding your task is.
Can I run an open AI model on my own computer?
Yes. Free tools let you download a model and run it locally with a simple command, often with a chat interface similar to ChatGPT. Mid-sized models now run on a single high-end graphics card, and smaller ones run on a decent laptop. The largest, smartest models still need expensive multi-card setups because the entire model has to fit in fast memory.
Is it cheaper to use open models?
It can be, in two ways. Many open models are available through inexpensive hosted services at a fraction of premium prices, which suits high-volume work. And above a certain scale, running the model yourself removes per-use fees entirely. But below that scale, paying per use is usually cheaper once you count the hardware and engineering time, so it is not automatically cheaper for everyone.
Why would a business choose an open model over a closed one?
Mainly for control. Open models can run entirely on the company's own hardware, so sensitive data never leaves the building, which matters for regulated industries. They can be fine-tuned on the company's own data, often cost less at scale, and prevent the business from being locked into one provider's prices and rules. The tradeoff is more setup work and, at the very top end, slightly lower capability.
Does open mean I can use the model for anything?
No. What you can do is set by the model's license, and these vary widely. Some permissive licenses allow free commercial use with no restrictions, while others limit large companies, restrict certain regions, or forbid commercial use altogether. Always check the specific license before building a product on a model.